Перевод аудио в текст онлайн и бесплатно
-
Зачем вообще нужно переводить аудио в текст?
-
Перевод аудио в текст при помощи связки Whisper + Colab
- Пошаговое руководство
-
Транскрибация видео в текст
-
Перевести Ютуб в текст
- Пошаговое руководство
Транскрибация – это перевод речи в текст. В данном контексте нет разницы, речь будет в видео- или аудиоформате.
Зачем вообще нужно переводить аудио в текст?
Сценарии применения:
- Если вы создатель контента и вам нужно наложить субтитры на видео.
- Из видеолекции или интервью сверстать статью.
- Семантичесий (т. е. смысловой) анализ видео.
Какие есть решения и что с ними не так?
Поисковики предлагают очень много решений этой задачи. Платные сервисы справляются достаточно хорошо.
Минусы бесплатных сервисов:
- Ограничение по длине речи.
- Долгое время перевода.
- Низкое качество (точность текста и речи).
Цель этой статьи – показать именно бесплатный способ. При этом получить качественный результат на выходе. На мой взгляд, самые главные преимущества предложенного ниже варианта – это довольно качественное распознавание разных голосов и точное определение таймкодов.
Перевод аудио в текст при помощи связки Whisper + Colab
Whisper – это модель машинного обучения для распознавания и транскрипции речи, созданная компанией OpenAI и выпущенная с открытым исходным кодом в сентябре 2022 года.
Colaboratory (или просто Colab) – сервис от Google, который позволяет писать и выполнять код Python в браузере.
Плюсы:
- не нужно никаких серверов и их настроек;
- бесплатный (с ограничениями) доступ к графическим процессорам GPU;
- раздавать доступ другим людям очень просто (так же, как Google Docs).
В этой статье предлагается техническое решение. Необязательно быть программистом, достаточно точно следовать по шагам. Думаю, любой справится.
Пошаговое руководство
- Зайдите на свой гугл драйв (нужна гугл почта).
- Нажмите на большую кнопку «+» в левом верхнем углу.
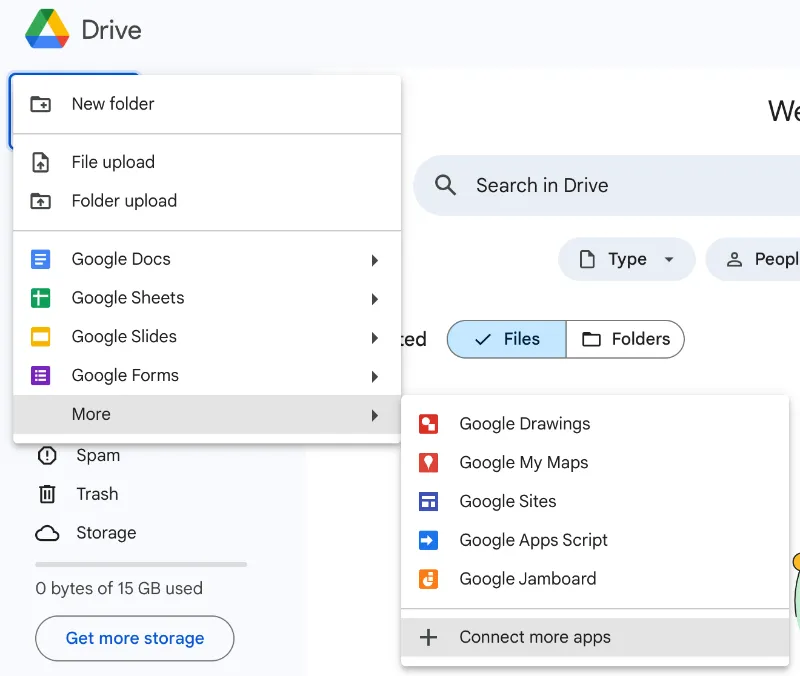
- В поиске найдите приложение Colaboratory.
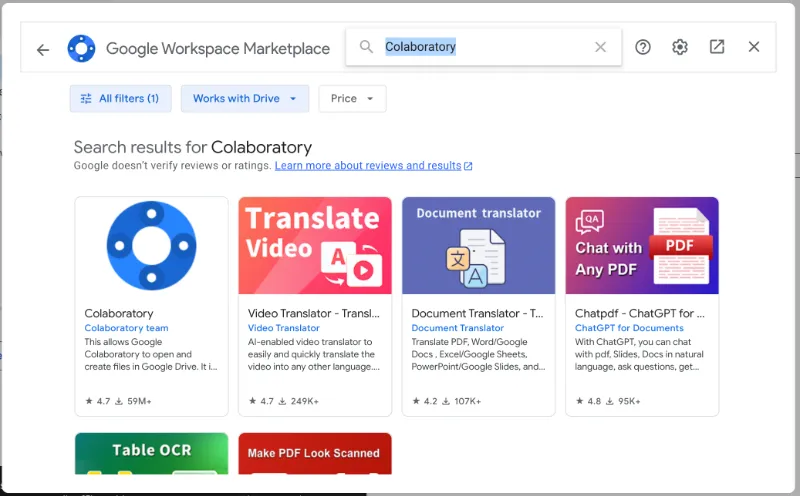
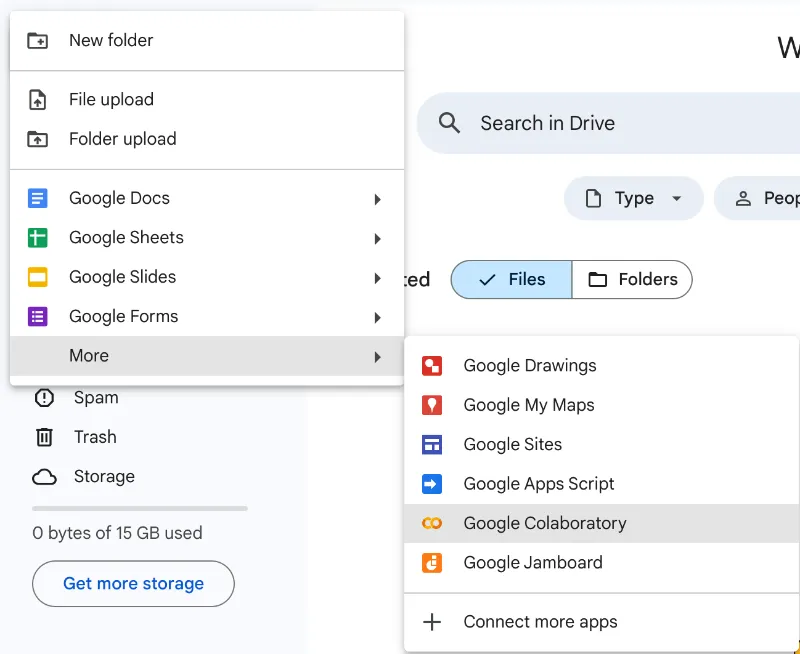
- Выберите его и нажмите «Установить».
- Опять нажмите на большую кнопку «+» в левом верхнем углу и выберите Google Colaboratory.
- Открывается страница с Colab-документом. Это такой же файл, как любой ваш гугл документ или гугл таблица. Поэтому этот файл автоматически сохранится на вашем гугл диске.
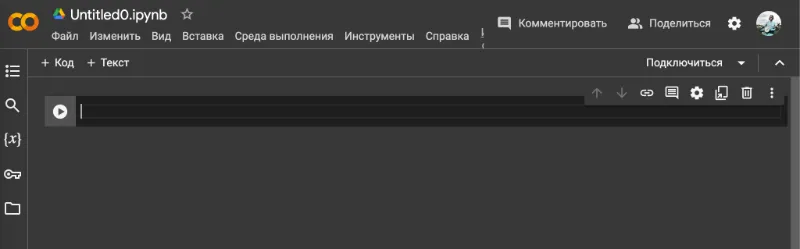
- В меню (в верхней части документа) выберите «Среда выполнения» -> «Сменить среду выполнения». Откроется окно, в нем выберите T4 GPU.
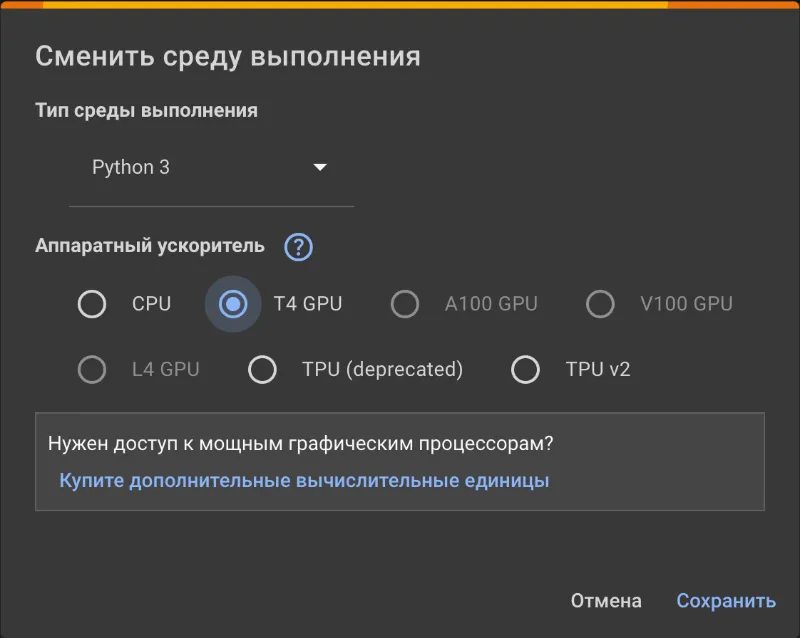
В правом верхнем углу должен появится знак T4.
- В поле (для ввода кода) введите команду:
!pip install git+https://github.com/openai/whisper.git
и нажмите слева иконку play.
Процесс займет около 1 минуты. - Добавьте новое поле для ввода кода.
В поле введите команду:pip install stable-ts
Stable-ts – это модификация библиотеки Whisper. Она тоже опенсоурсная. Используя стандартную библиотеку Whisper, столкнулся с проблемой неточных таймкодов. Например, в видео фраза «Привет» начинается на таймкоде 1:23:53, а whisper дает текстовую расшифровку с таймкодом 1:23:51. Для некоторых случаев это критичная разница. Stable-ts лучше решает проблему точности таймкодов. Не идеально, но лучше. - В левой колонке нажмите иконку папки. Боковая панель расширяется:
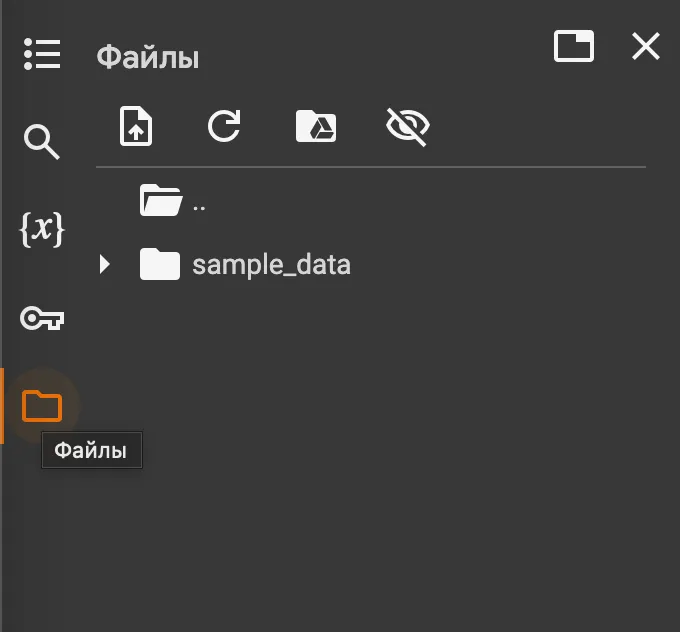
- Перетащите в боковую панель нужный аудио- или видеофайл. Появится предупреждение, что загруженные файлы будут в будущем удалены. Ок. Дождитесь загрузки файла. У меня файл 200 Мб загружается около 10 мин. Процесс загрузки файла можно отслеживать в нижней части панели.
- Добавьте еще одно поле для ввода кода и скопируйте этот код:
import stable_whisperFILENAME = "vv2.mp4" # название вашего файлаmodel = stable_whisper.load_model("medium")result = model.transcribe(FILENAME, language="ru", fp16=False, verbose=True)result.to_tsv(FILENAME + ".tsv") # TSVresult.save_as_json(FILENAME + ".json") # JSON
В переменной FILENAME укажите название файла. Он должен совпадать с названием файла, который вы загрузили. В коде подключаю модель medium. В описании открытого кода whisper есть таблица доступных моделей. Пробовал модель base с 74 млн параметров, но качество посредственное. Особенно заметно, когда речь невнятная или с акцентом. Библиотека stable-ts поддерживает 6 выходных форматов: srt, vtt, ass, tsv, txt, json. В коде сохраняю текст в 2 форматах: tsv и json. - Нажмите иконку Play. Начался процесс перевода из видео в текст.
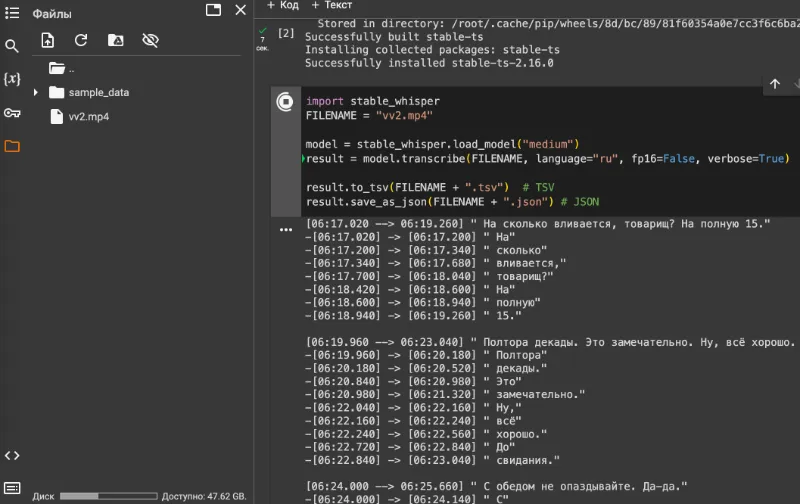
В процессе выполнения виден текст реплик. Полная фраза и ее тайм-код + отдельное слово и его тайм-код
Видео длительностью 1 час 30 минут переводилось около 10 минут. Это при условии, что вычисления выполнялись в среде T4 GPU. Иногда ресурсы заняты (если мы говорим про бесплатный тариф), тогда такой размер файла обрабатывается на обычном CPU, и процесс занимает около 2 часов. - После окончания транскрибации в левой панели появятся файлы с текстом.
Пример фрагмента текста из сгенерированного tsv-файла:193000 195200 А, инвалид, что вы теперь скажете?196240 197740 Простите.199560 200500 Закон есть закон.201120 201660 Пожалуйста,201960 202180 садитесь.202840 203680 Большое спасибо.204380 207220 Ах ты зрячий! Ты сейчас будешь слепой.
Качество вполне хорошее. Но лучше бегло пробежаться и проверить на явные ляпы.
Транскрибация видео в текст
Технически между видео и аудио разницы нет. Поэтому описанное выше решение подойдёт и для видеофайлов.
Перевести Ютуб в текст
У Ютуба есть встроенная функция транскрибации. Разверните описание видео. Снизу кнопка:
Но качество текста очень-очень не очень. Многие слова неверно переведены. Также нет разделения на голоса: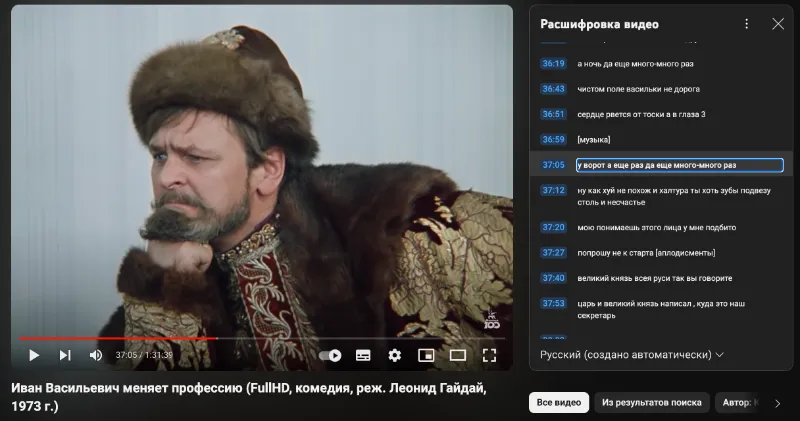
Чтобы качественно перевести ютуб-ролик в текст (на любой язык), можно также воспользоваться решением, описанным выше. Только с небольшим изменением. Вместо загружки своего файла можно при помощи библиотеки pytube скачать видео прямо с Ютуба.
Пошаговое руководство
- Выполните в Colab команду:
pip install pytube - Выполнить код:
from pytube import YouTubeurl = "https://www.youtube.com/watch?v=a50qT9bW2Qo"yt = YouTube(url)audio = yt.streams.filter(only_audio=True).first()audio.download()
Важно: не забудьте поменять адрес нужного вам ролика в переменной url.
После выполнения кода в левой панели должен появиться скачанный файл с Ютуба.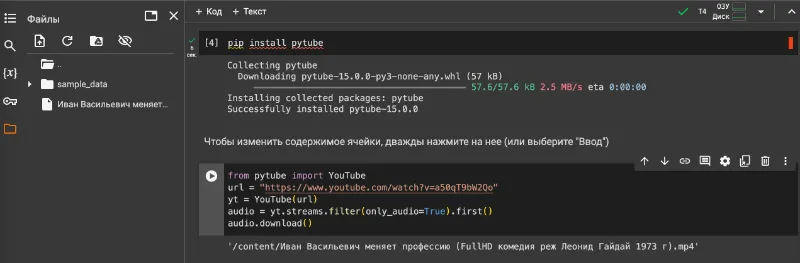
- Выполните код:
import stable_whisperFILENAME = "Иван Васильевич меняет профессию (FullHD комедия реж Леонид Гайдай 1973 г).mp4"model = stable_whisper.load_model("medium")result = model.transcribe(FILENAME, language="ru", fp16=False, verbose=True)result.to_tsv(FILENAME + ".tsv") # TSVresult.save_as_json(FILENAME + ".json") # JSON
Подождите минут 10 (если вычисления идут на T4 GPU), и текст будет готов.
Если у вас возникли трудности с запуском или вопросы, напишите на почту. Постараюсь помочь.